Dec 2, 2024
Dec 2, 2024
Creativity, a hallmark of human innovation, is increasingly critical in generative AI. While 2D text-to-image models excel in realism, creativity remains subjective and undefined. We propose the first quantifiable definition of computational creativity: generating novel concepts that challenge Open World Object Detectors (OWOD [?]). Expanding into 3D, we introduce creative 3D concept generation, addressing challenges in reconstructing unseen concepts. Extensive evaluations validate our approach’s superior creativity and fidelity. Overall, 16% more humans preferred our images on creativity and prompt-adherence compared to OpenAI’s DALL-E 3 [?] in our user study. This work redefines computational creativity, sets benchmarks, and opens new frontiers in generative AI for 3D content.
Creativity has long been considered a hallmark of human ingenuity, driving innovation across disciplines. With the rise of generative modeling, the challenge of bringing creativity to machines has become increasingly important. Machines should, and already can, help people generate new and meaningful ideas faster, explore a broader range of possibilities, and reduce personal bias. From designing imaginative 2D/3D concepts in entertainment and gaming to supporting ideation in engineering, computational creativity bridges the gap between human inspiration and machine precision, fostering new forms of collaboration and innovation.
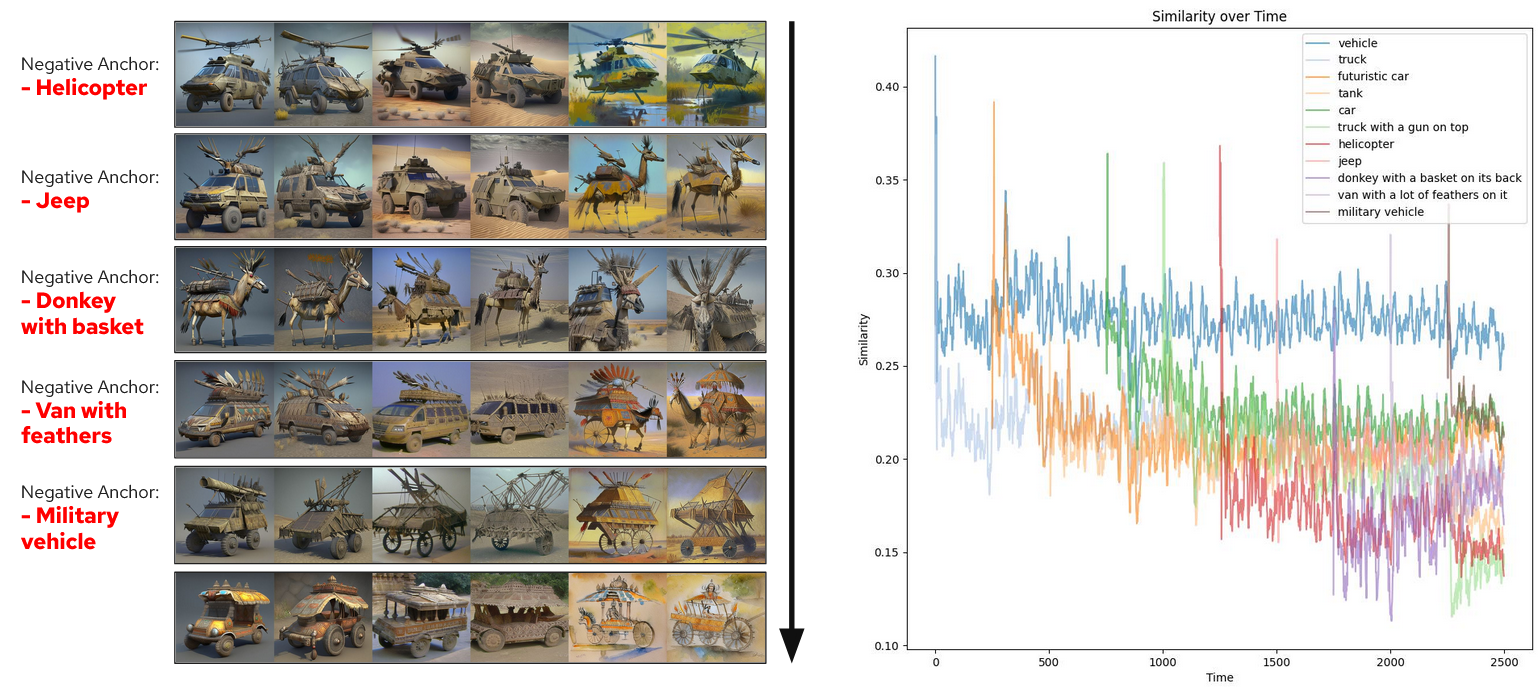
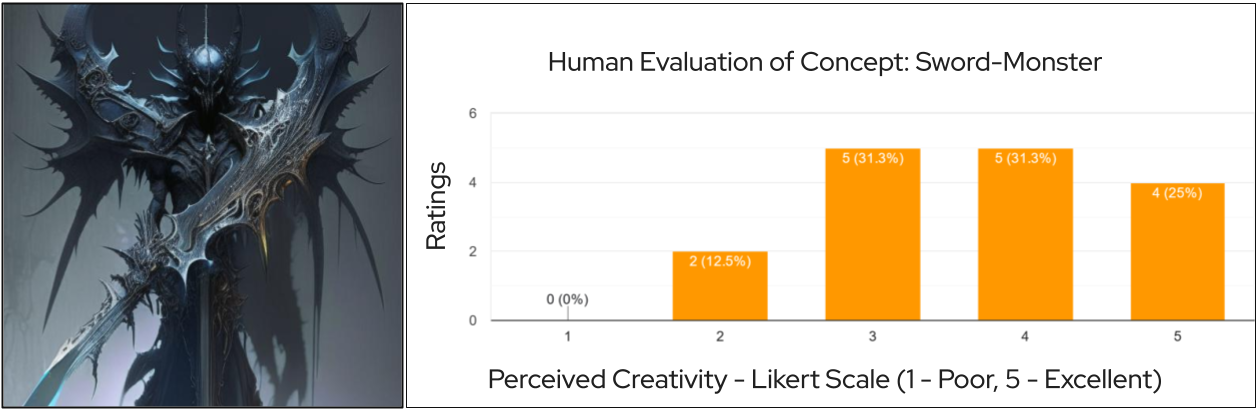
While 2D text-to-image generation has reached impressive levels of realism and diversity, creativity in these generations still remains a highly subjective and vague concept that these models are not able to explicitly exploit or get evaluated against. Even humans do not have a set definition for creativity still and largely vary in their evaluations of the same. This phenomenon is validated by our human study for rating perceived creativity of generations. Fig. 5 shows a large spread in human ratings even for a single concept. However, recently ConceptLab [?] introduced the task of creative text-to-image generation and made an attempt towards defining creativity in the context of text-to-image models for the first time. They define creativity as generating a new or imaginary concept that has never been seen before within a broad category (ex - generating a vehicle that looks different from all existing vehicles. See Fig. 2). This starting definition of computational-creativity still has a lot of ambiguities and no way to quantify creativity to any extent. Additionally, broad categories can often be viewed as generic re-touches or feature combinations by humans thus receiving a low score on creativity as seen in our MOS study Tab. 1.
In this paper we define the first quantifiable definition of computational creativity in the context of text-to-image models or generative AI, and also use it to improve the “creativity” of ConceptLab [?]. Open World Object Detection (OWOD [?]) is a method trained to identify objects that have not been introduced to it before as ‘unknown’, without explicit supervision and then incrementally learn them when a label is provided. These detectors can easily detect and classify concepts produced based on ConceptLab’s definition with high confidence but struggle with truly novel and creative concepts emerging out of our re-definition. Overall, our definition for computational creativity is this: imaginary, new concepts that have never been seen before and exist at the breaking point or failure mode of Open World Object Detectors are creative. To reach this, we employ a simple contrastive optimization strategy evolving inter-class broad concepts from ConceptLab’s definition.
The transition to creative 3D asset generation remains a formidable challenge and has not been explored so far. Addressing this gap is critical, as 3D concepts hold immense potential for industries such as entertainment, gaming, and engineering design. The ability to generate entirely novel 3D models from minimal input (like text, voice input) could redefine how creative assets are developed, enabling unprecedented ideation and innovation. So, we additionally introduce the task of creative 3D concept generation in this paper. This is inherently a difficult task to begin with but becomes harder as global generative priors are not usable anymore. This happens due to the creative concepts being never seen before during training of the 3D reconstruction model. Intuitively, local priors and epipolar attention based mechanisms [?] should provide a reasonable structure still since the images are still on a real-enough manifold that might intersect with that of the real images. We integrate advanced single-view to 3D reconstruction techniques for our pipeline that is capable of generating highly imaginative 3D assets. Extensive qualitative human assessments and quantitative comparisons demonstrate the superior creativity and fidelity of our method.
Overall, our work tackles the problem of defining a quantifiable form of computational-creativity then introduces the task of creative 3D concept generation. To summarize, we make the following contributions:
In this section, we go over the most closely related works and baselines for our method.
Text-to-image generative models have revolutionized the translation of textual descriptions into visual content, each advancing the field with unique approaches and capabilities. There are a wide variety of such models [?, ?, ?]. Kandinsky [?] is a transformer-based architecture emphasizing multi-modal understanding to blend textual and visual semantics. Kandinsky 2 [?] introduces enhancements like improved image fidelity and better semantic alignment, addressing limitations in context interpretation. Stable Diffusion (SD) [?]) also follows diffusion-based generative capabilities. SD 1.5 is known for its stable and versatile performance, while 2.1 improved rendering quality, especially for fine details and complex scenes. DALLE-3 XL [?] recently set a new benchmark achieving unparalleled image quality and adherence to prompts. It also embeds robust ethical safeguards, balancing creative flexibility with responsible use.
ConceptLab [?] is a novel framework for creative concept generation that leverages diffusion prior models [?, ?] and Vision-Language Models (BLIP-2 [?]) to produce unique and imaginative outputs. It frames concept generation as an optimization problem constrained by latents, ensuring that new concepts are both distinct and aligned with broader categorical themes.
Joseph et al [?] introduced a novel framework for object detection in open-world scenarios, where the system must detect both known and previously unseen object classes. Its approach combines known object classification with the ability to identify and cluster unknown objects in a unified pipeline. In a recent work by Sun et al [?] the persistent issue of low recall on unknown objects leading to misclassification into known classes is treated explicitly. This method is used for our computational creativity and 2D generation pipeline adapted from [?].
Single view to multi-view Zero123 [?] pioneered the single view to consistent multi-view generation using diffusion models. SyncDreamer [?] builds on Zero123’s diffusion model for the same task. It models the joint probability distribution of multi-view images, enabling simultaneous generation of consistent images through a synchronized reverse diffusion process.
Neural Radiance Fields. Built on NeRFs [?], SinNeRF [?] is designed to operate using only a single image. It employs a semi-supervised learning approach that introduces geometry and semantic pseudo-labels to guide the training process.
3D Gaussian Splatting (3DGS [?]) introduces a real-time high-quality rendering pipeline enabling novel-view synthesis from multiple images. This method represents scenes using 3D Gaussians defined by position, anisotropic covariance, color, and opacity. A key advantage of 3DGS is its high training and rendering efficiency. Splatter-image [?] is a single view method built on top of 3DGS that employs a neural network to generate a corresponding 3D Gaussian for each pixel, effectively creating a “Splatter Image”.
CLAY [?] is designed to generate high-quality 3D assets from various inputs, including text descriptions, images, and 3D primitives like voxels and point clouds. It employs a multi-resolution Variational Autoencoder (VAE [?]) and a latent Diffusion Transformer (DiT [?]) to capture complex 3D geometries and material properties.
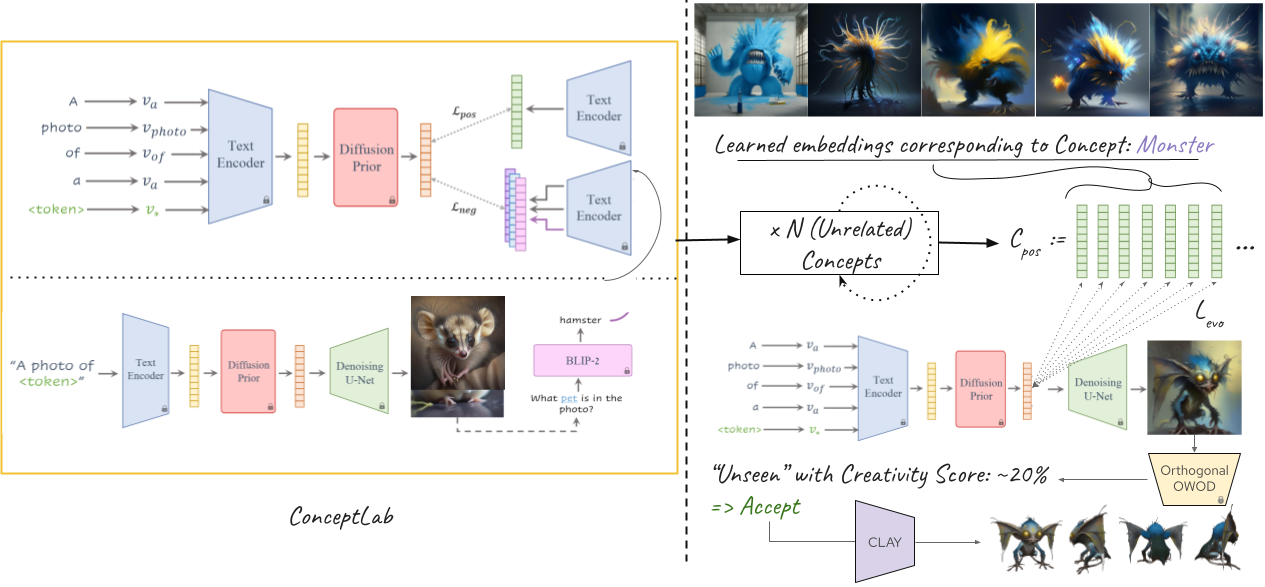
In this section, we describe our open world detector’s role (Sec. 3.1) in our pipeline, then describe our evolutionary 2D concept generation pipeline in Sec. 3.2 then discuss our 3D reconstruction method in Sec. 3.3. The overall architecture is shown in Fig. 3.
A recent method [?] built on RandBox [?] exploits disentanglement by orthogonality [?, ?, ?] to separate objectness and class-information in the feature as well as prediction stage. This in addition with a decorrelation loss helps [?] achieve significantly higher unknown class recall (U-Recall) and hence overall better object discovery in open world object detection scenarios. This is the exact operation theater for our work or for achieving (extreme) creativity.
We simply use [?] as a discarding mechanism for our generated concepts. Concepts scoring higher than 35% confidence or softmax score are discarded. The rationale behind this mechanism is this: if a concept generated from a learned embedding is somewhat similar to a specific seen class-category, it is most likely that it will achieve a higher confidence score even though its label is unknown.
We rely on ConceptLab [?] as our main backbone and generate concepts across a range of broad categories including: vehicle, monster, food, cyborg, pet, animal, weapon, building and art.
ConceptLab exploits the Diffusion Prior framework from Ramesh et al [?] that allows the text encoding and image embedding to exist in the same latent space to learn a new concept . In this latent space, a contrastive learning scheme is carried out between user-specified prompt () converted to token embedding using CLIP’s text encoder () as follows: . The same conversion to the latent space is carried out for all the automatically found (by BLIP-2 [?]) negative embeddings . The overall objective for this latent space contrastive learning is given as follows:
|
| (1) |
where is the controlling or influence hyper-parameter set at X and is the inner-product distance measure given by:
|
| (2) |
where is the Diffusion Image Prior model from [?]. Periodically, the learned latent () is sent to the Image generation diffusion network () which produces the new concept and then BLIP-2 appends a negative constraint to of size .
It should be noted that all networks in this pipeline are frozen during training and only a single learnable latent code () exists that is shifted away from all and pulled towards or kept within the bounds of .
Similar to ConceptLab’s evolution technique of positive anchors only contrastive optimization in the latent space, we evolve the concepts from the above unrelated broad categories together, unlike ConceptLab that evolves within the broad categories. The modified objective similar to [?] is given by:
|
| (3) |
Note that no negative optimization or shifting away from labels is done here. We propose to extend this loss with a model-based creativity loss using the Orthogonal Open World Object Detector [?]in the future.
For generating 3D reconstructions from the above 2D concepts we tried a number of different methods. Firstly, we evaluated SyncDreamer [?], which is a method for generating multiple views from a single view. This required alpha matting the 2D images we generated from concept lab. Because SyncDreamer models a joint distribution of the different views, this is likely a necessity due to the difficulty of modeling background details in this distribution. An example of this alpha matting process can be seen in Fig. 7. We then used a NeRF [?] to generate the 3D reconstruction from the multiple views. We also evaluated a number of single view to 3D reconstruction methods. One method we tried was SinNeRF [?] which adapts a NeRF to the single view task. We also tried Splatter-Image which uses 3D gaussian splatting [?] as a method for generating a 3D model from a single view. The method we found to perform the best was CLAY [?] which is what we use in our for the 3D reconstructor in our pipeline in Fig. 3.
ConceptLab [?] uses the Kandinsky 2.1 [?] with CLIP ViT-L/14 model [?] as the backbone. Training is performed on a single NVIDIA 4090 RTX for up to 2500 training steps using a batch size of 1 and a fixed learning rate of 0.0001 similar to [?]. For our base concept generation Eq. (1), we set = 1 and generate images at a resolution of px. For all experiments, we only evolve a single child generation using 20-30 samples generated from each parent concept. For our 3D reconstruction pipeline, we employ CLAY’s [?] online demo with single view prompting mode of operation without changing the material prompt for the Material Diffuser therein.
A working or computational definition of creativity is extremely challenging to achieve as even humans don’t implicitly agree on a single definition and are heavily shaped by inherent biases and experiences. An instance from our user study demonstrates the same phenomenon in Fig. 5. However, with our re-definition of creativity (a stepping stone) and use of [?] as a threshold for selecting evolved concepts, we carry out a preliminary user study to see whether our concepts are deemed creative enough subject to individuals’ definitions of creativity (unknown to us).
Our user study has two distinctions from ConceptLab’s: a) We ask the users to rate the perceived creativity of these generations within the limit of the provided prompt. Contrarily, ConceptLab only asks for prompt-adherence within their user study. b) We compare against more recent and larger T2I methods: DALL-E 3 and Stable Diffusion 2.1 compared to ConceptLab [?] Kandinsky 2 and Stable Diffusion 1.5. To design of our user study we manually crafted positive and negative prompts for the other text-to-image baselines as shown in the qualitative comparison in Fig. 4. We used a total of 24 images (8 per method) for comparison and asked 16 users to rate the (perceived) level of creativity in each generation within the bounds of the prompt.
| Method | Ours | DALL-E 3 XL | SD 2.1 |
| Average Rating () | 3.088 | 2.743 | 2.563 |
Results obtained in Tab. 1, against much stronger baseline methods, show a 16% preference for our strategy. Even though vanilla training regimes of ConceptLab reduce the CLIP [?] similarity of specific instances of a broad concept as shown in Fig. 2, open world object detectors easily classify the generated concepts as unknown with a high confidence score. However, when the same vehicle concept is evolved with an animal concept (Fig. 4), the evolutions receive a lower confidence score as they are extreme cases of OOD samples and confuse the shapeness+appearance and class orthogonality paradigm as the learned embedding produces shapes that are more varied over different seed generations.
In addition to our inter-class evolution, we demonstrate a useful feature for expanding creativity. We demonstrate that evolving generated concepts with real ‘known’ images is also possible and produces meaningful yet creative concepts. This is shown in Fig. 6.
We demonstrate a qualitative comparison of 3D reconstructions from single views of our concepts in Fig. 9.
For 3D reconstruction we used the creative concepts generated from the prior 2D stage. We evaluated our method on evolved creative concepts: “animal+building,” “animal+vehicle,” “robot+food,” and “animal+monster”.
SyncDreamer. For generating the 3D reconstructions using SyncDreamer [?], we needed alpha matting or background removal, as shown in Fig. 7, to generate the multiple views. This process even though erroneous and a large source of error, is critical for most single view to multi-view methods. Adding to the aforementioned issue, 3D assets reconstructed using such methods struggle with complex (real or synthetic), out-of-distribution (OOD) images. A crucial feature that is not useful for our use case is global 3D spatial feature processing or the learned prior since the images are OOD and have unseen before textures, shapes, lighting and shadows. 3D reconstruction failure from this method is shown in Fig. 8
We selected images that had good background removal to ensure fair comparison of the 3D assets (not the quality of the matting process). For generating the multiple views we set the initial camera elevation angle parameter empirically as . We conducted tests on parameter values using the “building” concept (shown in Fig. 7) which we found to provide the best reconstructions for SyncDreamer. Classifier free guidance scales had little variation on the fidelity of reconstructions and used the default 2.0 for all our tests. Crop size which affects how the object in the input image gets resized was also a parameter we did not notice to have a significant impact thus we used the default square-crop of 200px.
Splatter-image [?]. We used default parameters for this 3D Gaussian Splatting [?] based single view reconstruction method trained on the large open-source Objaverse-XL dataset [?].
SinNeRF [?]. We use default parameters as the authors claim SinNeRF to generalize across single views with their dynamic view-transforming attention based architecture with the conventional MLP. SinNeRF perfomed poorly in our 3D experiments.
CLAY [?]. We used CLAY’s online demo to produce 3D assets as the code has not been open-sourced yet. We aim to tune the hyperparameters and potentially upgrade CLAY to use local epipolar attention [?] to further improve the quality of reconstructions. CLAY benefits from a large-scale high quality dataset. Additionally, they separate the geometry and texture generation processes which makes this method well suited to our task. It is challenging for these models to reconstruct objects that are sufficiently different from the training datasets. Thus, CLAY benefits from its extensive pretraining which allows for robustness to out of domain (OOD) distributions. Dividing the problem into smaller tasks also helps achieve OOD robustness.
We define computational creativity in the context of generative T2I models. By integrating Open World Object Detectors (OWOD [?, ?]) as a filtering mechanism with ConceptLab as the main backbone of the framework, we achieve 16% higher user preference over existing state-of-the-art T2I baselines [?, ?] on creativity and prompt-adherence. We further extend this creative concept generation paradigm to 3D using generative priors [?].
One limitation of our work is that, while we attempt to push closer to a quantitative measure for creativity, the subjectivity of creativity still makes it an open-research problem to come up with a working definition that is quantifiable and useful for generative T2I models. Another limitation is that highly detailed scenes are still challenging for most single-view reconstruction methods. Additionally, background reconstruction is an open-MVS problem that our work also suffers from.
For future work, we intend to integrate OWOD into from Eq. (3) for our creative concept generator. We also want to perform extended quantitative studies into the creativity of our 3D reconstructions using 3D-CLIP [?] by extending a measure of creativity first proposed by ConceptLab [?] to 3D. Exploring local epipolar attention blocks similar to [?] within CLAY’s [?] geometry diffusion model could potentially lead to fine-grained 3D reconstructions, critical for complex non-rigid scenes with varying ambient conditions.