R(
4.3 On the Convergence Rate of FKL
KL-divergence as a loss function has various convergence rates under different distributions of and . Any distribution property could have an impact to the convergence rate so that it may be difficult to find a way to change the head and tail gap of the two distributions without bringing other property difference of the two distributions. Due to the limited resources for LLM training, it is usually unrealistic to run as many as possible of epochs that could reach optimal performance. Therefore, we mainly focus on the beginning stage of the training and hypothesize some conditions that are not too harsh but also under which it is more fair to compare the performance differences largely brought by the head and tail distribution gap.
Definition 4.1: Hypothesis Conditions
Suppose there is a constant ,
And we give the definition of head H and tail T of a probability as
Definition 4.2
the cutoff index between head and tail is , which may vary in different scenarios. Each of Head and tail can be furthur divided into to groups as
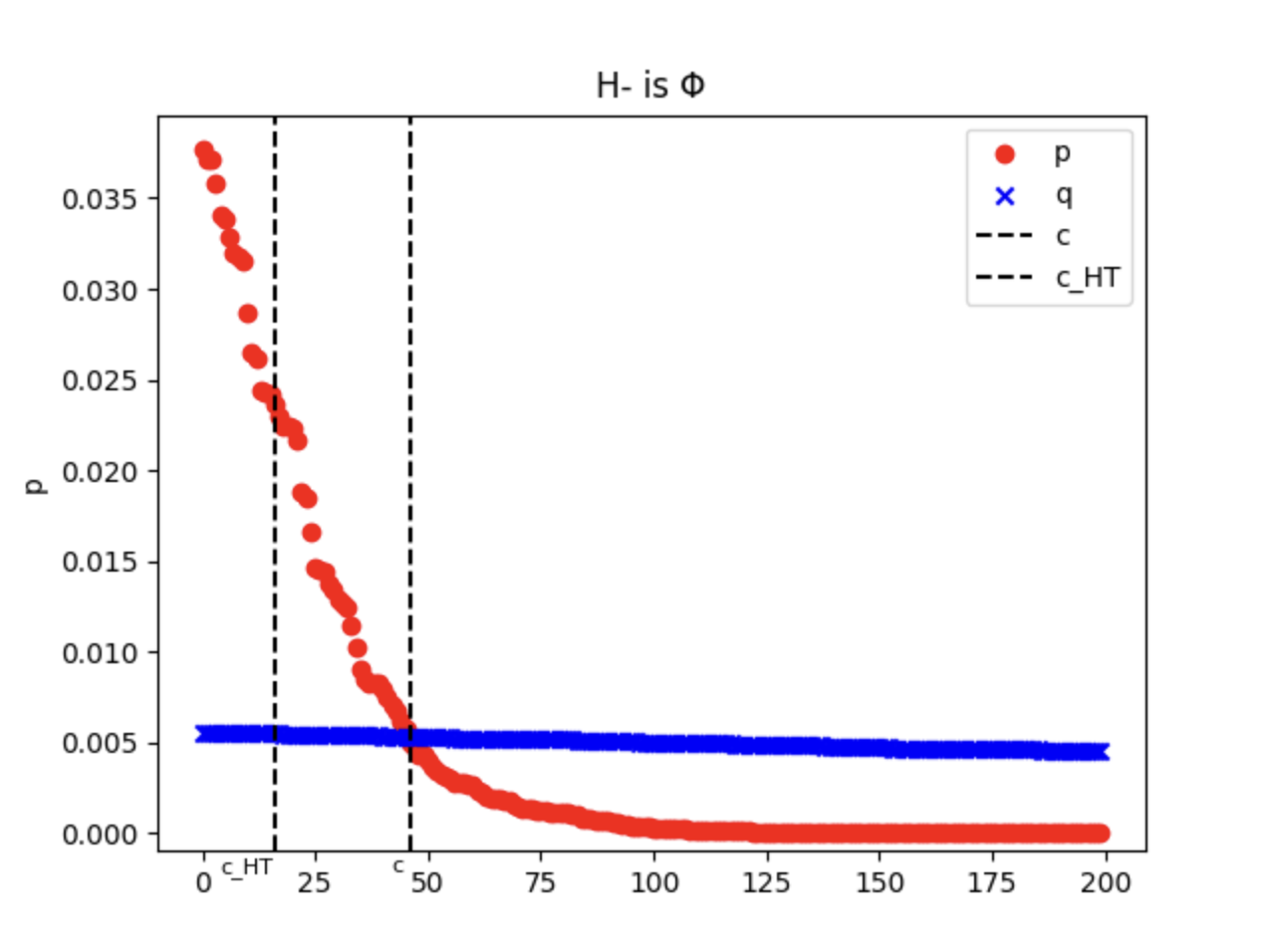
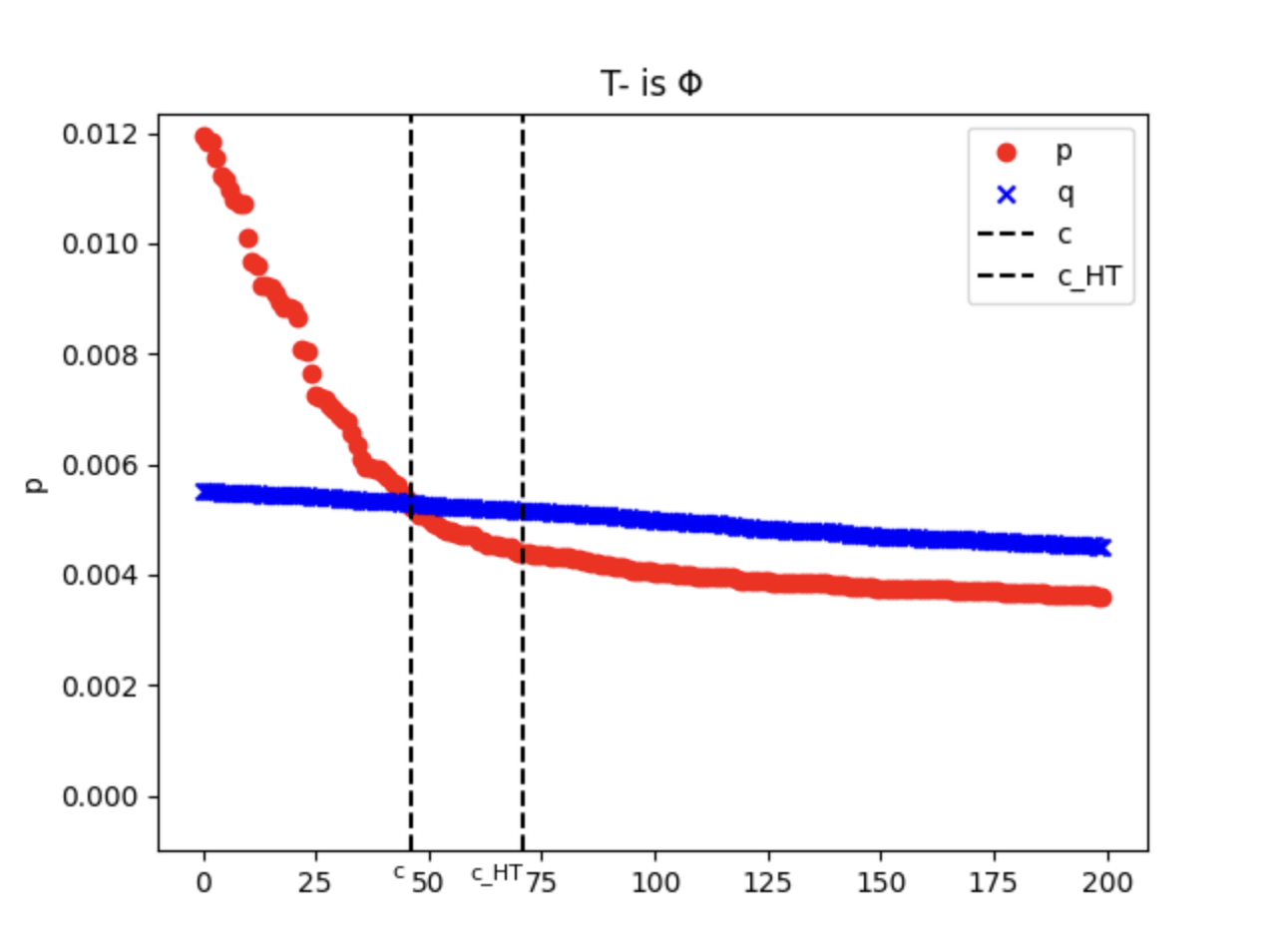
And define the two types of gaps
and
between p and q as
Definition 4.3
Lemma 4.2
In this work, we focus on
as the gap for FKL, which is also the same one used in [1]. We can
see there can be only two possible scenarios for the head and tail gap,
or
. They
can be both true but never be both false. See Figure 1 for a better description.
And
satisfies the following properties.
Lemma 4.3: FKL’s gap properties
Then we prove B in ?? is bounded by the total gap and is not related to the gap.
Lemma 4.4: The upperbound of
Finally we show that B is in different upperbound when the difference between head gap and tail gap varies.
Lemma 4.5
We have
By ?? and ??, we prove that when the head gap is larger than the tail gap, B has a lower upperbound so that FKL converges faster.
4.4 On the Convergence Rate of RKL
Similar to last section, we need to analyze B under RKL by different head and tail distribution
gap. Unfortunately, RKL’s gradient is much more complicated than FKL hence we didn’t find a
way to do so using the gap in ??, which is from the AKL paper[1]. We need to start from finding a
better way to describe the head and tail distribution gap between q and p for RKL.
Stimulated by the fact of that it is more susceptible to the probability mass of q, we give the RKL’s definition of head H and tail T as
Definition 4.4: RKL’s head and tail
Suppose q is in non-increasing order,
Definition 4.5: RKL’s gap
Lemma 4.6: RKL’s gap properties
?? can be interpreted as RKL ’s head and tail gap difference is centered at . So the gap of RKL should have a center of mass that is closer to the tail part. Then we give the B’s uppperbound for RKL as the total gap.
Lemma 4.7: The upperbound 1 of
So B is actually not only bounded by the total gap, but also reverse KL divergence. By combining ?? with ??, we may have a bound that is more meaningful.
Lemma 4.8: The upperbound 2 of
?? tells that only if the total gap gets smaller for the classes with , which actually accounts for the gap of the ”long tail” part, B has a lower upperbound then RKL may converges faster. That said, RKL’s performance may be mostly bounded by the tail gap rather than the difference between the head and tail gap, which matches the common understanding for RKL that it is more vulnerable for the part where p has a low value.
4.5 Summary
Intuitively, a KL divergence loss function aims to minimize the gap between two distributions so that the total gap should be highly related to the complexity and performance. However, the total gap is usually different from the KL divergence in value. Firstly we use the convergence rate theorem and Rademacher complexity contraction lemma to analyze this problem. Then we give the appropriate definitions of gap for FKL and RKL respectively. By strictly analysis of FKL, we prove that the total gap is indeed a key factor to the performance under different head and tail gap distributions for it. For RKL, we find that it works better when the long tail gap is smaller, which consists of the tail part and also some of the head part where . Although it is still difficult to compare the complexity of FKL and RKL for a more strict proof of AKL’s performance, another interesting extension may be that can we use the gap definitions in this work as a loss function instead of FKL, RKL or AKL?
5 Conclusion
In this work, we have advanced the theoretical understanding of knowledge distillation for large
language models by revisiting and extending the analysis of KL divergence loss functions. First, we
proved that the proposed Adaptive KL framework retains the same global convergence properties
as both forward and reverse KL. Then, by introducing the convergence guarantee of
Jensen–Shannon divergence , we provided one more option of divergence loss as an alternative
symmetric and bounded objective. Lastly, we invested quite some effort to carefully derive explicit
bounds for forward and reverse KL through convergence-rate analysis based on stochastic
nonconvex optimization and Rademacher complexity, which reveals that FKL converges
faster when the student’s overestimation concentrates more in the head region than
the tail, and RKL’s convergence may be predominantly governed by the gap in the
long-tail.
Together, these results may be hopefully helpful on understanding if and why each divergence favors different regions of the discrepancies between the teacher and student distribution, partly justifying the adaptive convex-combination strategy of AKL. The performance analysis result for RKL in this work implies that it may be bounded mostly by the tail part, which does not necessarily support the idea that RKL may performs better if the tail gap is larger than the head gap. Beyond validating AKL’s theoretical soundness, we raised a question whether any of the gap definitions in this work helps in building a better divergence loss function. For potential future work, one may try to look for more theoretical insights and empirical evidence on these gaps.
References
[1] Taiqiang Wu, Chaofan Tao, Jiahao Wang, Runming Yang, Zhe Zhao, and Ngai Wong. Rethinking kullback-leibler divergence in knowledge distillation for large language models, 2024. URL https://arxiv.org/abs/2404.02657.
[2] Saeed Ghadimi and Guanghui Lan. Stochastic first- and zeroth-order methods for nonconvex stochastic programming, 2013. URL https://arxiv.org/abs/1309.5549.
[3] Guillaume Garrigos and Robert M. Gower. Handbook of convergence theorems for (stochastic) gradient methods, 2024. URL https://arxiv.org/abs/2301.11235.
[4] Liam Madden, Emiliano Dall’Anese, and Stephen Becker. High probability convergence bounds for non-convex stochastic gradient descent with sub-weibull noise, 2024. URL https://arxiv.org/abs/2006.05610.
A ?? Proof
The convergence condition for AKL is given by,
We can consider the coefficients for AKL formula as scalar weights such that
Sufficiency Condition. Put in the above equation to evaluate its value,
Necessity Condition. We need to show that if the differential is , then it must hold that
Let , then
and
(2) - (1) we have
However log(x) is a strictly concave function so that its secant slope cannot always be a constant of unless
Added above together for all j
This completes the proof.
B ?? Proof
For the first term
For the second term
Putting these together
C ?? Proof
D ?? Proof
If ,
If ,
So
Citation
If you find this analysis useful and want to cite it in your work, you can use the following BibTeX entry: