1. FlashAttention on Economical GPUs
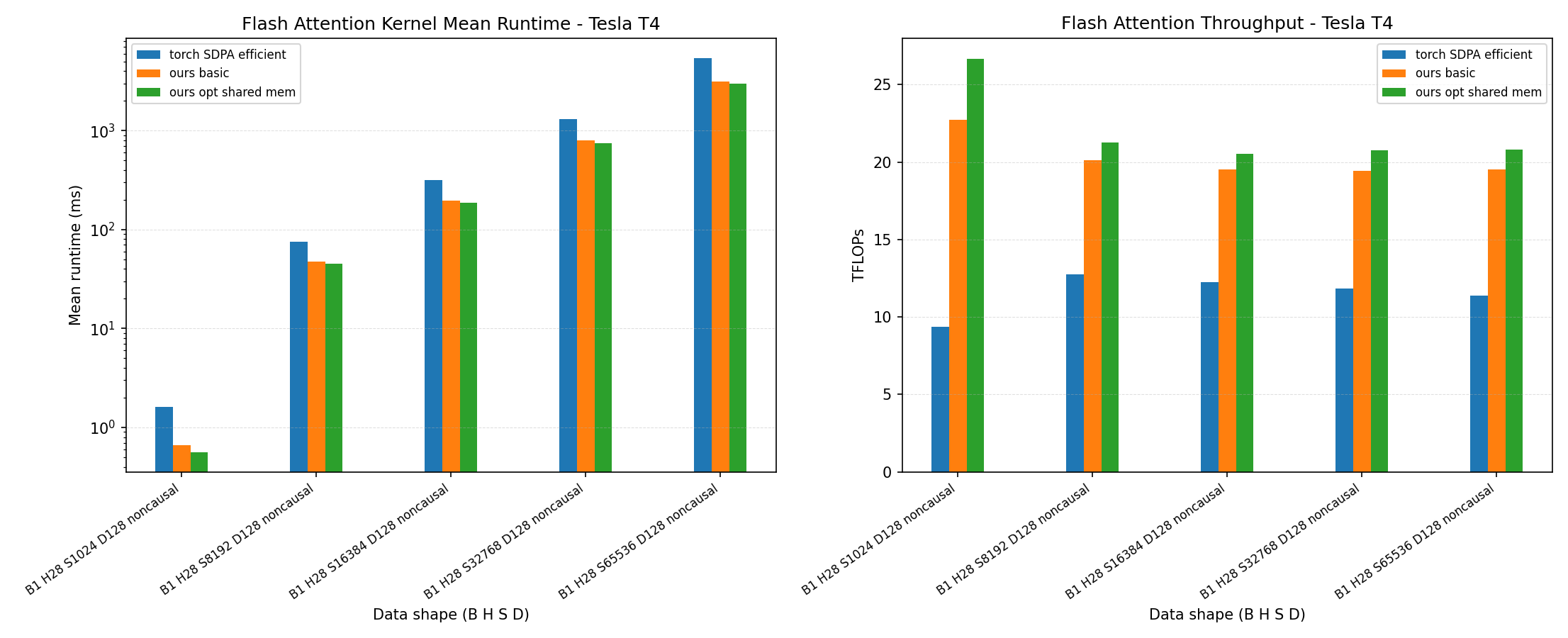
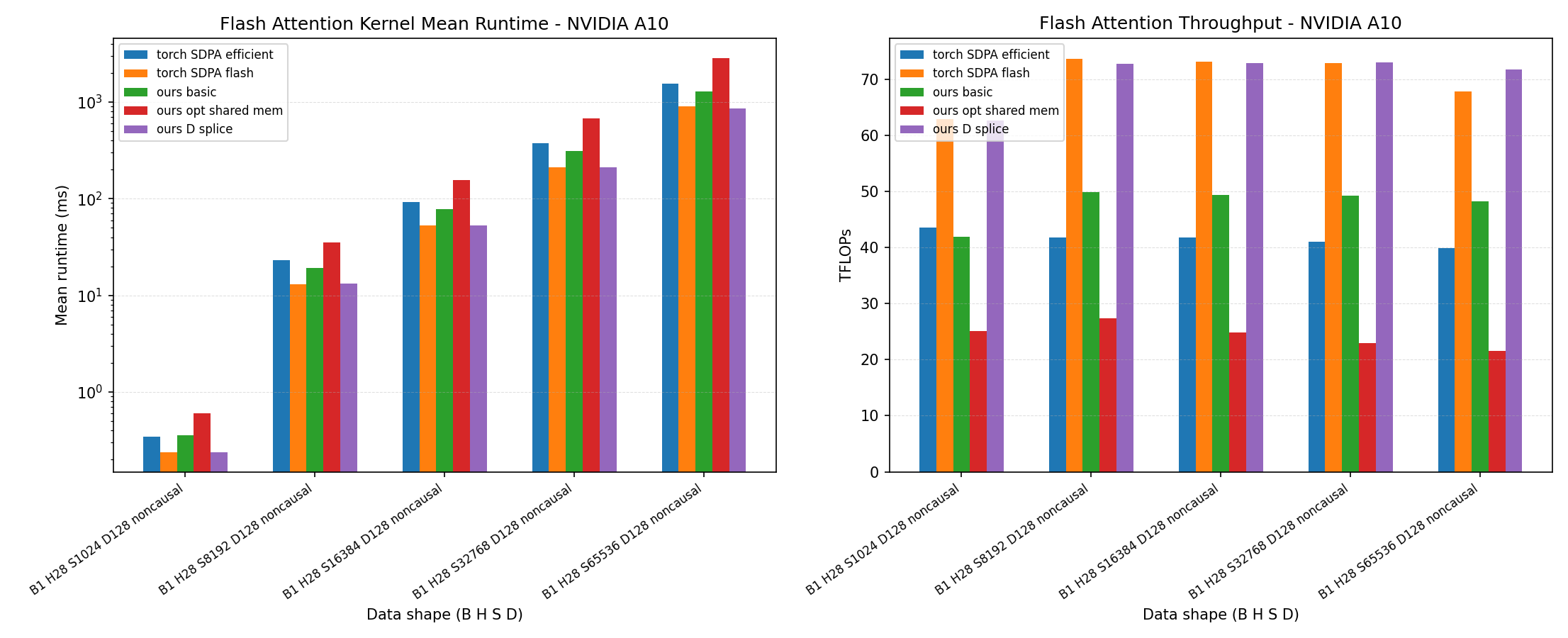
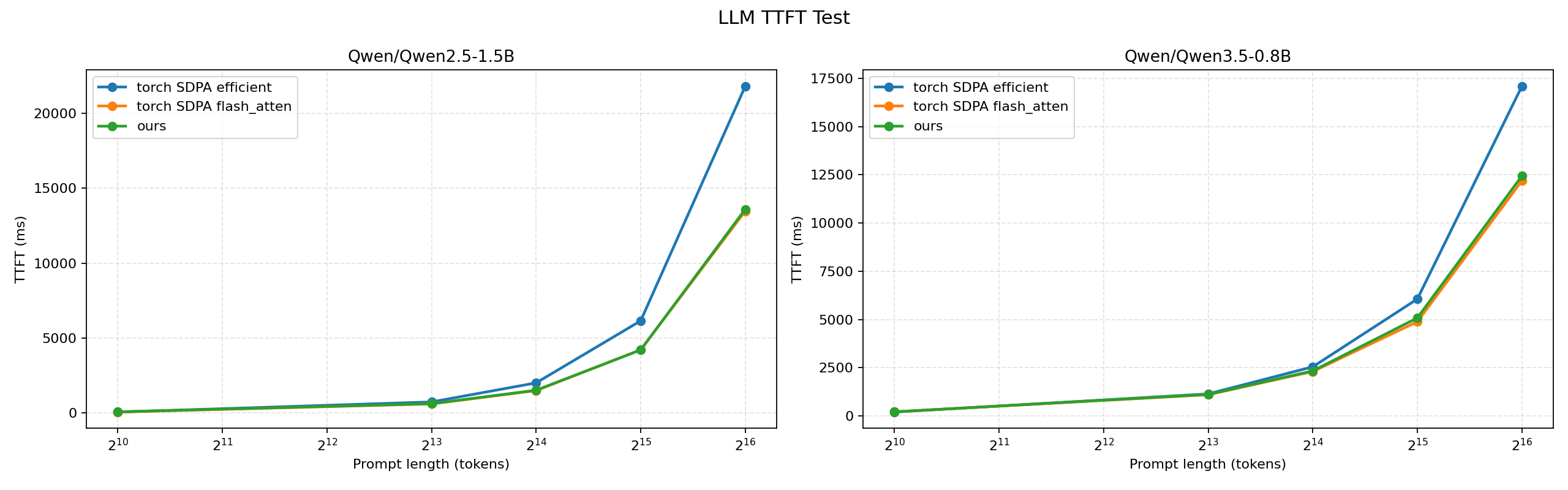
flash-attn-economical-gpu implements Triton-based FlashAttention kernels that beat or reach comparable performance with popular libraries such as PyTorch FlashAttention SDPA across economical GPU architectures including Turing and Ampere; Our Triton MMA kernels outperforming torch.matmul by up to 80% on Turing and 25% on Ampere, optimized Triton SDPA leading tested PyTorch SDPA backends on Turing for D=128 and D=256, sliced Triton SDPA reaching near PyTorch FlashAttention performance on Ampere, and LLM TTFT benchmarks on Qwen2.5 and Qwen3.5 where the sliced Triton kernel stays close to PyTorch FlashAttention while clearly faster than PyTorch efficient SDPA.
2. LLM(VLM) RLVR and reward hacking detection
Task: Fine-tune two multi-modal LLMs with RL under different reward designs; make sure one reward hacks but the other does not. Then trained a VLM and some fixed-length soft tokens for reward hacking detection based on multi-vector embeddings.
Implementation: RL framework developement based on OpenR1 + trl; other components implemented by myself from scratch.
Algorithms: GRPO, Selective Sample Replay (similar to Prioritized Replay), Matryoshka Embedding, MetaEmbed, LoRA.
Models: Qwen3-VL (8B/4B/2B), Qwen3(8B/4B/1.7B), GPT-OSS-20B, LLaVA-OneVision-1.5 (8B/4B).
GPUs: 8*A100
Dataset: Used a math dataset as a base and filtered for difficult problems only (pass@K < 0.1 before RL). After RL, the reward hacking detection dataset is synthesized using data generated from both models. The multi-modal reward hacking dataset is open-accessible here, and a text-only version here.
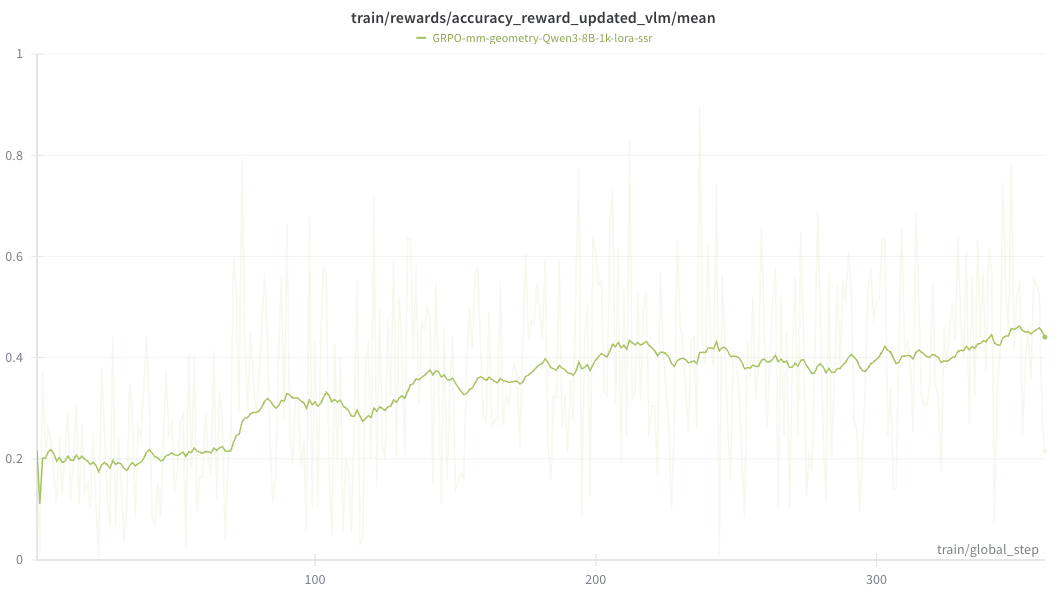
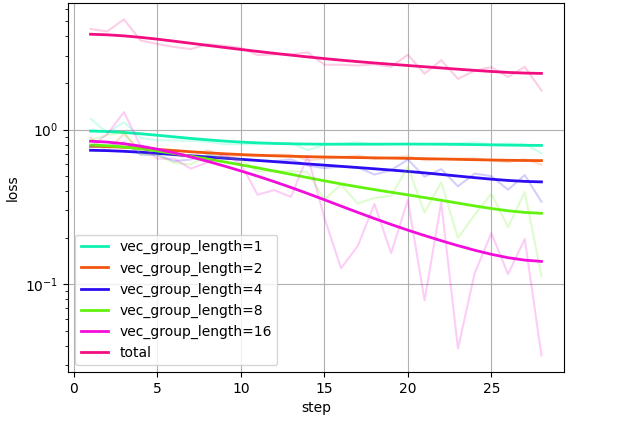
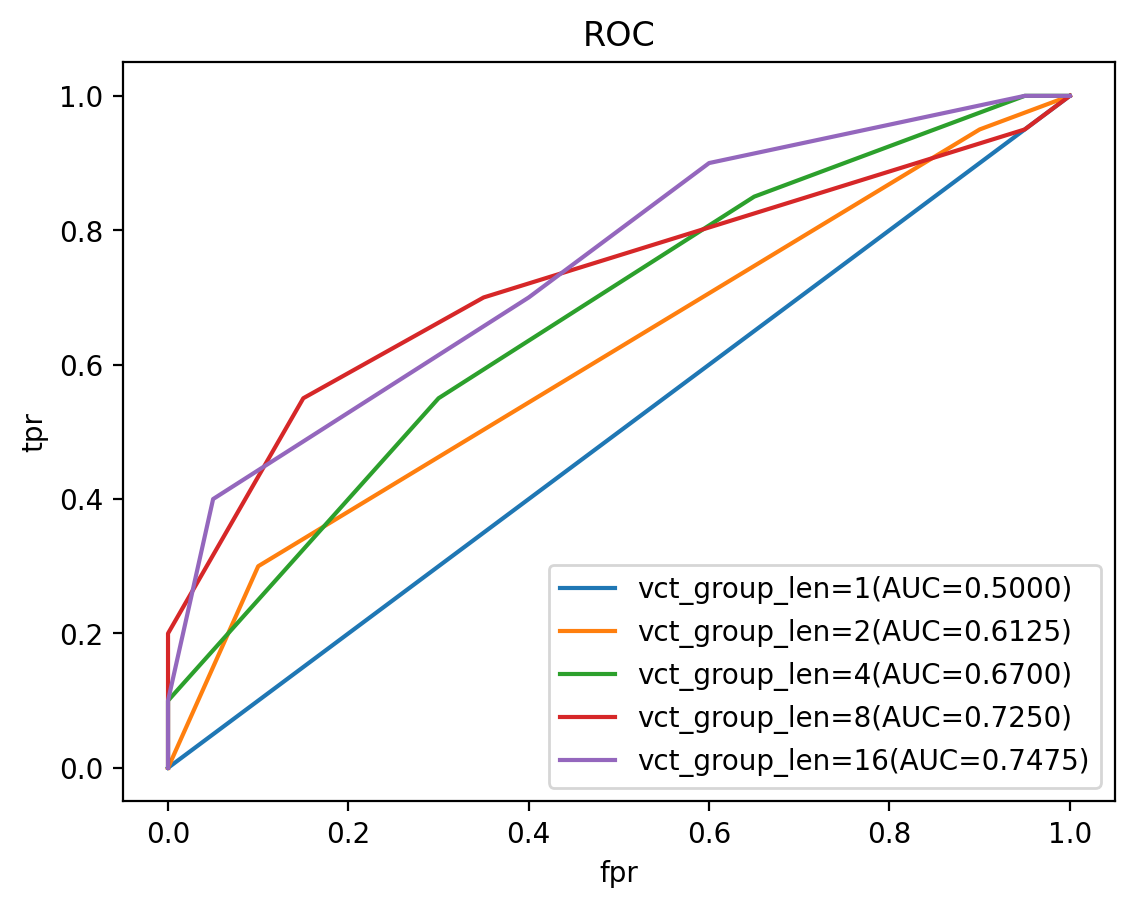
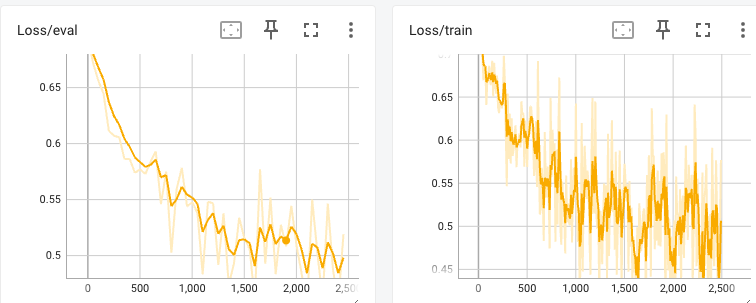
Training Results: The RL training curve (w/o reward hacking) and the reward hacking detection training curve under different vector length.
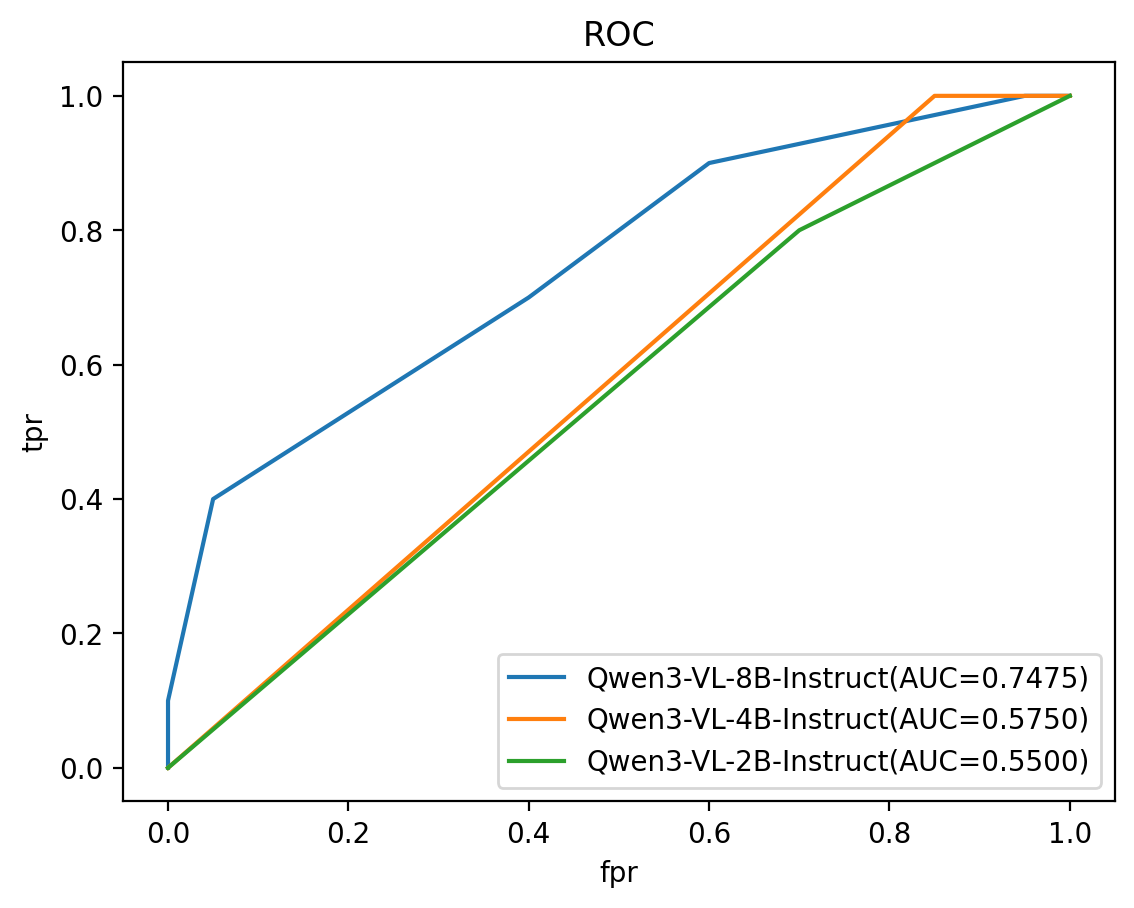
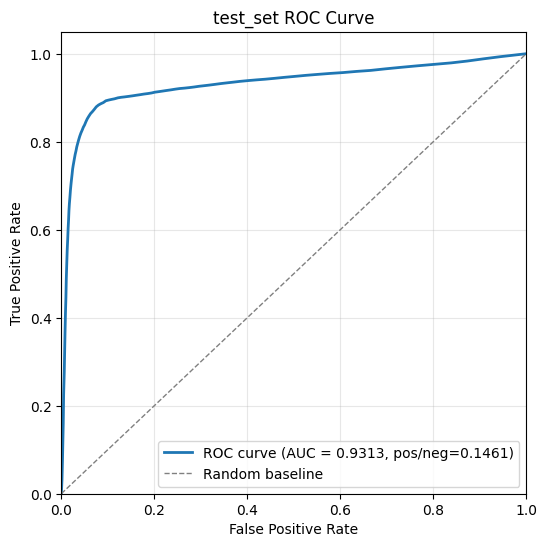
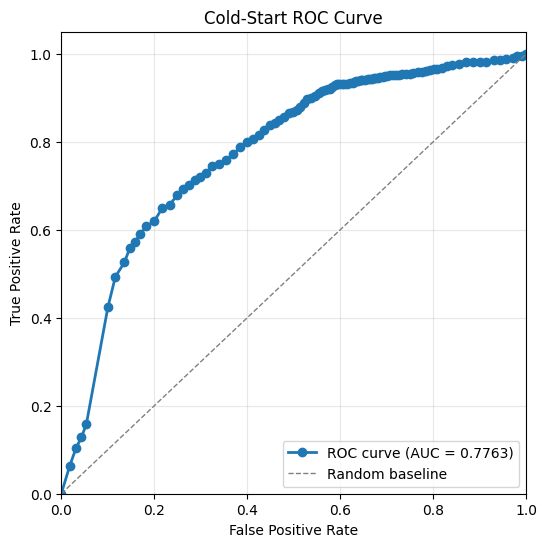
Evaluation Results: AUC > 0.74 for a Qwen3-VL-8B backbone. AUC scales well with the backbone parameter size.
3. LLM RLHF with NanoGPT+PPO
Task: Lowering the probabilities of certain keywords appearing using reinforcement learning.
Implementation: I implemented the NanoGPTLMActorCriticPolicy from scratch, a policy network initialized using pretrained NanoGPT model parameters. Firstly trained the reward model. Then A value network similar to the reward model but with a different language head layer. PPO is used for RL training.
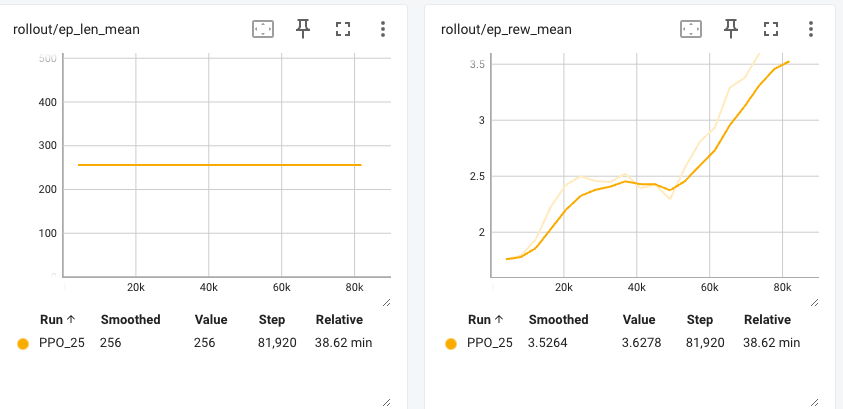
Results: The expected cumulative reward increases during training. No divergence loss is used here so early stop is adopted. After training, only 9% of the answers contain keywords — a 60% drop compared to the model before RL. No human noticeable text quality downgrade was found.